404 Not Found is one of the most basic signals an API can send.
It says: “this endpoint does not exist”.
When that signal is wrong, everything built on top of the API becomes harder to reason about.
This test looks trivial. In practice, it is broken far more often than teams expect — including in mature, production systems.
What was tested
Rentgen takes a known, valid API request and deliberately corrupts the URL path by appending random segments that should not exist. The request is otherwise unchanged.
The expectation is simple and unambiguous:
- If the endpoint does not exist, the API must return
404 Not Found
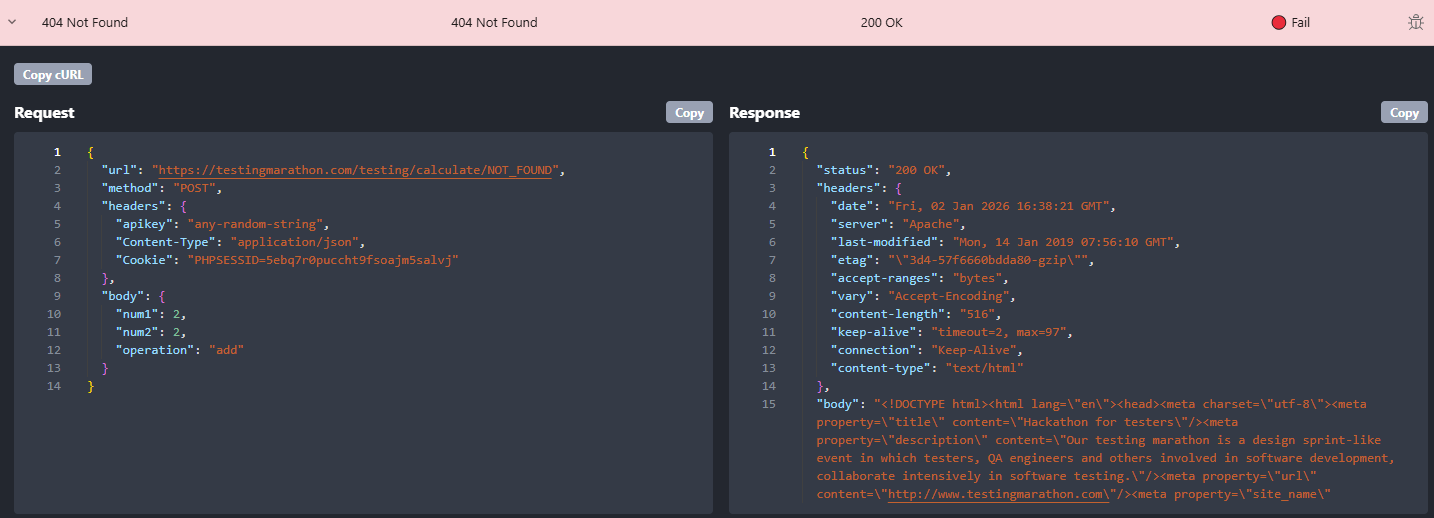
What Rentgen found
- TEST: 404 Not Found Handling
- Expected:
404 Not Found - Actual:
200 OK - Status: 🔴 Fail
Why this is a failure (not an edge case)
Returning 200 OK for a non-existent endpoint is not harmless.
It tells the client:
“This request was valid and processed correctly.”
That message is false. And false signals are far more damaging than explicit errors.
The debugging trap
Imagine a small typo in the URL:
- a missing slash
- a wrong version segment
- a copied link with an extra character
Instead of a clean 404, the client receives 200 OK.
What happens next is predictable:
- developers inspect request headers
- they validate payloads
- they check authentication and permissions
- they re-run requests again and again
The real problem — the endpoint does not exist — is the one thing nobody questions.
The operational cost nobody notices
Now imagine this at scale.
Clients are calling non-existent URLs. Integrations are misconfigured. Old mobile versions are still in the wild.
But your API responds with 200 OK.
In monitoring systems and dashboards:
- everything looks healthy
- no error spikes
- no alerts
Meanwhile: users complain, partners get frustrated, and engineers get blamed — because logs and metrics insist everything is fine.
Why this happens in real systems
Most of the time, this behavior is accidental.
Common causes include:
- catch-all routes that return default responses
- frameworks configured to fall back to a generic handler
- reverse proxies or gateways rewriting paths
- “temporary” logic added to keep clients from breaking
Over time, the API stops enforcing its own boundaries.
Why this is a real bug
APIs are contracts. A correct contract must clearly separate:
- existing resources
- invalid requests
- non-existent endpoints
When non-existent endpoints return 200 OK,
the API loses the ability to say “no”.
And without that, clients cannot reliably detect mistakes.
How other teams usually discover this
Rarely through tests.
Much more often through:
- customer complaints
- support tickets
- confusing Grafana dashboards
- long debugging sessions with no clear root cause
By the time someone notices, the behavior is already depended on by clients — making it painful to fix.
How to fix it
The rule is simple:
- If the endpoint does not exist, return
404 Not Found - Do not reuse success responses for unknown routes
- Ensure gateways and proxies do not mask missing paths
If your framework supports automatic 404 handling, make sure it is not overridden by custom routing logic.
Why Rentgen checks this
Because this bug hides in plain sight.
It doesn’t crash systems. It doesn’t trigger alerts. It quietly drains engineering time and erodes trust in monitoring.
Rentgen deliberately generates invalid URLs to verify that the API still tells the truth when something does not exist.
Final thoughts
A correct 404 is not about being strict.
It’s about being honest.
When an API can clearly say “this endpoint does not exist”, every other response becomes easier to trust. And trust, in production systems, is worth far more than pretending everything is OK.