Trimming is one of those checks that looks too small to matter. Until you ship an integration that assumes data is clean — and it isn’t.
This is not a “nice to have” style preference. It is input canonicalization. It affects uniqueness, idempotency, caching keys, searches, and downstream clients that make perfectly reasonable assumptions.
What this test is — and what it is not
This is not about formatting the user’s input to be polite. It is about preventing logically identical values from becoming different values in storage and integrations.
Rentgen’s trimming test asks a simple question: when a string contains leading or trailing whitespace, does the API normalize it or reject it explicitly?
What was tested
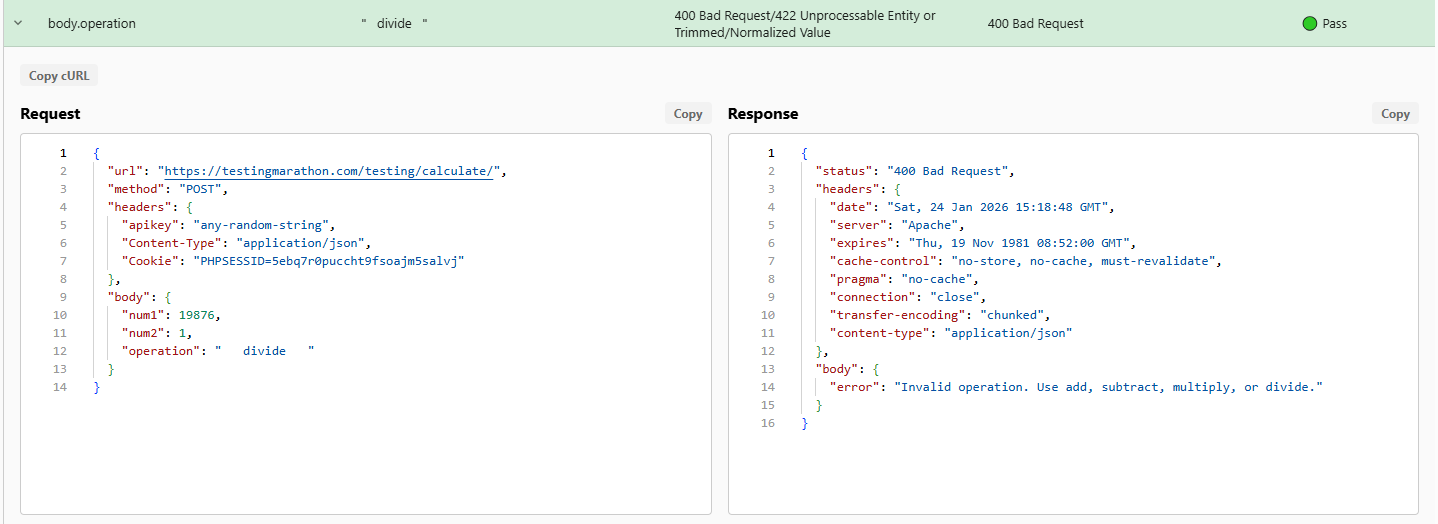
Rentgen sent a request where body.operation contained extra whitespace:
the value was valid after trimming, but invalid as-is.
- Field:
body.operation - Injected value:
" divide " - Expected behavior: reject as invalid or normalize before validation
The key here is not the calculator example itself. The same pattern applies to any API that accepts user-provided strings: usernames, external IDs, tags, product codes, email-like identifiers, slugs, names, “unique” keys.
What Rentgen found
The API returned an error for the whitespace-padded value, effectively treating it as a different operation. That is a valid choice only if the API contract explicitly defines whitespace as meaningful.
In most real systems, whitespace is not meaningful — it is accidental. The problem starts when the backend accepts accidental whitespace in some endpoints, but not in others.
Why this matters
Here is the classic integration failure: your API accepts a string field that must be unique. Backend validation exists. A database unique index exists. Everything looks correct. Then a user makes a tiny mistake and sends the same value with an extra space.
If the API stores the value as-is, you can end up with two records that are logically identical to the client but different to the database. When you later return the dataset, the client sees duplicates and breaks (or worse — merges incorrectly).
This is how you get production bugs that are extremely hard to reproduce: all data “looks” correct to humans, but the system treats it as different because of invisible characters.
Why most teams miss this
Because manual testing is clean by default. Testers and developers type values carefully. They copy-paste correct examples. They do not intentionally add whitespace to a value they already know is valid.
And when issues do appear, they are usually blamed on “client-side mistakes” instead of being treated as a backend contract and canonicalization problem.
Two correct outcomes
For trimming tests, there are only two outcomes that scale:
- Reject as invalid (400 / 422) — if whitespace is forbidden and must be explicit in the contract.
- Normalize (trim) before validation and storage — if whitespace is accidental and should not create new values.
The dangerous outcome is the third one: accepting untrimmed values in some places and trimming them in others. That creates inconsistencies between create/update/search/list endpoints.
What else matters besides a simple space
Trimming is not just about the obvious " ".
Real systems break on whitespace variants that humans do not notice:
- Tabs and newlines (
\t,\n,\r) - Non-breaking space (NBSP,
U+00A0) - Unicode whitespace (thin spaces, zero-width characters, copy-paste artifacts)
- Double spaces inside values (normalization rules must be consistent if you choose to compress whitespace)
If you normalize, you must normalize consistently — across create, update, search, and comparisons. If you reject, you must reject consistently — and return a clear error that helps clients fix input.
Why this check exists in Rentgen
Because trimming bugs are not “edge cases”. They are common, human, and inevitable — and they quietly create data integrity problems that surface later, when multiple systems depend on the same identifiers.
Rentgen runs this test because it is easy to forget, easy to dismiss, and expensive to debug after the fact.
Final thoughts
Invisible characters create visible failures. If your API treats accidental whitespace as a new value, you will eventually store duplicates, break uniqueness assumptions, and ship integration bugs that feel “random”.
Reject it or normalize it. But never leave it undefined.